实战二:接口鉴权
实战二:接口鉴权
面向对象分析(OOA)、面向对象设计(OOD)、面向对象编程(OOP),是面向对象开发的三个主要环节。在前面的章节中,我对三者的讲解比较偏理论、偏概括性,目的是让你先有一个宏观的了解,知道什么是 OOA、OOD、OOP。不过,光知道“是什么”是不够的,我们更重要的还是要知道“如何做”,也就是,如何进行面向对象分析、设计与编程。
在过往的工作中,我发现,很多工程师,特别是初级工程师,本身没有太多的项目经验,或者参与的项目都是基于开发框架填写 CRUD 模板似的代码,导致分析、设计能力比较欠缺。当他们拿到一个比较笼统的开发需求的时候,往往不知道从何入手。
对于“如何做需求分析,如何做职责划分?需要定义哪些类?每个类应该具有哪些属性、方法?类与类之间该如何交互?如何组装类成一个可执行的程序?”等等诸多问题,都没有清晰的思路,更别提利用成熟的设计原则、思想或者设计模式,开发出具有高内聚低耦合、易扩展、易读等优秀特性的代码了。
所以,本节结合一个真实的开发案例,从基础的需求分析、职责划分、类的定义、交互、组装运行讲起,将最基础的面向对象分析、设计、编程的套路给你讲清楚,为后面学习设计原则、设计模式打好基础。
案例介绍和难点剖析
假设,你正在参与开发一个微服务。微服务通过 HTTP 协议暴露接口给其他系统调用,说直白点就是,其他系统通过 URL 来调用微服务的接口。有一天,你的 leader 找到你说,“为了保证接口调用的安全性,我们希望设计实现一个接口调用鉴权功能,只有经过认证之后的系统才能调用我们的接口,没有认证过的系统调用我们的接口会被拒绝。我希望由你来负责这个任务的开发,争取尽快上线。”
leader 丢下这些话就走了。这个时候,你该如何来做呢?有没有脑子里一团浆糊,一时间无从下手的感觉呢?为什么会有这种感觉呢?我个人觉得主要有下面两点原因。
1. 需求不明确
leader 给到的需求过于模糊、笼统,不够具体、细化,离落地到设计、编码还有一定的距离。而人的大脑不擅长思考这种过于抽象的问题。这也是真实的软件开发区别于应试教育的地方。应试教育中的考试题目,一般都是一个非常具体的问题,我们去解答就好了。而真实的软件开发中,需求几乎都不是很明确。
我们前面讲过,面向对象分析主要的分析对象是“需求”,因此,面向对象分析可以粗略地看成“需求分析”。实际上,不管是需求分析还是面向对象分析,我们首先要做的都是将笼统的需求细化到足够清晰、可执行。我们需要通过沟通、挖掘、分析、假设、梳理,搞清楚具体的需求有哪些,哪些是现在要做的,哪些是未来可能要做的,哪些是不用考虑做的。
2. 缺少锻炼
相比单纯的业务 CRUD 开发,鉴权这个开发任务,要更有难度。鉴权作为一个跟具体业务无关的功能,我们完全可以把它开发成一个独立的框架,集成到很多业务系统中。而作为被很多系统复用的通用框架,比起普通的业务代码,我们对框架的代码质量要求要更高。
开发这样通用的框架,对工程师的需求分析能力、设计能力、编码能力,甚至逻辑思维能力的要求,都是比较高的。如果你平时做的都是简单的 CRUD 业务开发,那这方面的锻炼肯定不会很多,所以,一旦遇到这种开发需求,很容易因为缺少锻炼,脑子放空,不知道从何入手,完全没有思路。
对案例进行需求分析
实际上,需求分析的工作很琐碎,也没有太多固定的章法可寻,所以,我不打算很牵强地罗列那些听着有用、实际没用的方法论,而是希望通过鉴权这个例子,来给你展示一下,面对需求分析的时候,我的完整的思考路径是什么样的。希望你能自己去体会,举一反三地类比应用到其他项目的需求分析中。
尽管针对框架、组件、类库等非业务系统的开发,我们一定要有组件化意识、框架意识、抽象意识,开发出来的东西要足够通用,不能局限于单一的某个业务需求,但这并不代表我们就可以脱离具体的应用场景,闷头拍脑袋做需求分析。多跟业务团队聊聊天,甚至自己去参与几个业务系统的开发,只有这样,我们才能真正知道业务系统的痛点,才能分析出最有价值的需求。不过,针对鉴权这一功能的开发,最大的需求方还是我们自己,所以,我们也可以先从满足我们自己系统的需求开始,然后再迭代优化。
现在,我们来看一下,针对鉴权这个功能的开发,我们该如何做需求分析?
实际上,这跟做算法题类似,先从最简单的方案想起,然后再优化。所以,我把整个的分析过程分为了循序渐进的四轮。每一轮都是对上一轮的迭代优化,最后形成一个可执行、可落地的需求列表。
1. 第一轮基础分析
对于如何做鉴权这样一个问题,最简单的解决方案就是,通过用户名加密码来做认证。我们给每个允许访问我们服务的调用方,派发一个应用名(或者叫应用 ID、AppID)和一个对应的密码(或者叫秘钥)。调用方每次进行接口请求的时候,都携带自己的 AppID 和密码。微服务在接收到接口调用请求之后,会解析出 AppID 和密码,跟存储在微服务端的 AppID 和密码进行比对。如果一致,说明认证成功,则允许接口调用请求;否则,就拒绝接口调用请求。
2. 第二轮分析优化
不过,这样的验证方式,每次都要明文传输密码。密码很容易被截获,是不安全的。那如果我们借助加密算法(比如 SHA),对密码进行加密之后,再传递到微服务端验证,是不是就可以了呢?实际上,这样也是不安全的,因为加密之后的密码及 AppID,照样可以被未认证系统(或者说黑客)截获,未认证系统可以携带这个加密之后的密码以及对应的 AppID,伪装成已认证系统来访问我们的接口。这就是典型的“重放攻击”。
提出问题,然后再解决问题,是一个非常好的迭代优化方法。对于刚刚这个问题,我们可以借助 OAuth 的验证思路来解决。调用方将请求接口的 URL 跟 AppID、密码拼接在一起,然后进行加密,生成一个 token。调用方在进行接口请求的的时候,将这个 token 及 AppID,随 URL 一块传递给微服务端。微服务端接收到这些数据之后,根据 AppID 从数据库中取出对应的密码,并通过同样的 token 生成算法,生成另外一个 token。用这个新生成的 token 跟调用方传递过来的 token 对比。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。
这个方案稍微有点复杂,我画了一张示例图,来帮你理解整个流程。

3. 第三轮分析优化
不过,这样的设计仍然存在重放攻击的风险,还是不够安全。每个 URL 拼接上 AppID、密码生成的 token 都是固定的。未认证系统截获 URL、token 和 AppID 之后,还是可以通过重放攻击的方式,伪装成认证系统,调用这个 URL 对应的接口。
为了解决这个问题,我们可以进一步优化 token 生成算法,引入一个随机变量,让每次接口请求生成的 token 都不一样。我们可以选择时间戳作为随机变量。原来的 token 是对 URL、AppID、密码三者进行加密生成的,现在我们将 URL、AppID、密码、时间戳四者进行加密来生成 token。调用方在进行接口请求的时候,将 token、AppID、时间戳,随 URL 一并传递给微服务端。
微服务端在收到这些数据之后,会验证当前时间戳跟传递过来的时间戳,是否在一定的时间窗口内(比如一分钟)。如果超过一分钟,则判定 token 过期,拒绝接口请求。如果没有超过一分钟,则说明 token 没有过期,就再通过同样的 token 生成算法,在服务端生成新的 token,与调用方传递过来的 token 比对,看是否一致。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。
优化之后的认证流程如下图所示。

4. 第四轮分析优化
不过,你可能会说,这样还是不够安全啊。未认证系统还是可以在这一分钟的 token 失效窗口内,通过截获请求、重放请求,来调用我们的接口啊!
你说得没错。不过,攻与防之间,本来就没有绝对的安全。我们能做的就是,尽量提高攻击的成本。这个方案虽然还有漏洞,但是实现起来足够简单,而且不会过度影响接口本身的性能(比如响应时间)。所以,权衡安全性、开发成本、对系统性能的影响,这个方案算是比较折中、比较合理的了。
实际上,还有一个细节我们没有考虑到,那就是,如何在微服务端存储每个授权调用方的 AppID 和密码。当然,这个问题并不难。最容易想到的方案就是存储到数据库里,比如 MySQL。不过,开发像鉴权这样的非业务功能,最好不要与具体的第三方系统有过度的耦合。
针对 AppID 和密码的存储,我们最好能灵活地支持各种不同的存储方式,比如 ZooKeeper、本地配置文件、自研配置中心、MySQL、Redis 等。我们不一定针对每种存储方式都去做代码实现,但起码要留有扩展点,保证系统有足够的灵活性和扩展性,能够在我们切换存储方式的时候,尽可能地减少代码的改动。
5. 最终确定需求
到此,需求已经足够细化和具体了。现在,我们按照鉴权的流程,对需求再重新描述一下。如果你熟悉 UML,也可以用时序图、流程图来描述。不过,用什么描述不是重点,描述清楚才是最重要的。考虑到在接下来的面向对象设计环节中,我会基于文字版本的需求描述,来进行类、属性、方法、交互等的设计,所以,这里我给出的最终需求描述是文字版本的。
调用方进行接口请求的时候,将 URL、AppID、密码、时间戳拼接在一起,通过加密算法生成 token,并且将 token、AppID、时间戳拼接在 URL 中,一并发送到微服务端。
微服务端在接收到调用方的接口请求之后,从请求中拆解出 token、AppID、时间戳。
微服务端首先检查传递过来的时间戳跟当前时间,是否在 token 失效时间窗口内。如果已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求。
如果 token 验证没有过期失效,微服务端再从自己的存储中,取出 AppID 对应的密码,通过同样的 token 生成算法,生成另外一个 token,与调用方传递过来的 token 进行匹配;如果一致,则鉴权成功,允许接口调用,否则就拒绝接口调用。
这就是我们需求分析的整个思考过程,从最粗糙、最模糊的需求开始,通过“提出问题 - 解决问题”的方式,循序渐进地进行优化,最后得到一个足够清晰、可落地的需求描述。
如何进行面向对象设计?
我们知道,面向对象分析的产出是详细的需求描述,那面向对象设计的产出就是类。在面向对象设计环节,我们将需求描述转化为具体的类的设计。我们把这一设计环节拆解细化一下,主要包含以下几个部分:
划分职责进而识别出有哪些类;
定义类及其属性和方法;
定义类与类之间的交互关系;
将类组装起来并提供执行入口。
实话讲,不管是面向对象分析还是面向对象设计,理论的东西都不多,所以我们还是结合鉴权这个例子,在实战中体会如何做面向对象设计。
1. 划分职责进而识别出有哪些类
在面向对象有关书籍中经常讲到,类是现实世界中事物的一个建模。但是,并不是每个需求都能映射到现实世界,也并不是每个类都与现实世界中的事物一一对应。对于一些抽象的概念,我们是无法通过映射现实世界中的事物的方式来定义类的。
所以,大多数讲面向对象的书籍中,还会讲到另外一种识别类的方法,那就是把需求描述中的名词罗列出来,作为可能的候选类,然后再进行筛选。对于没有经验的初学者来说,这个方法比较简单、明确,可以直接照着做。
不过,我个人更喜欢另外一种方法,那就是根据需求描述,把其中涉及的功能点,一个一个罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,可否应该归为同一个类。我们来看一下,针对鉴权这个例子,具体该如何来做。
在上一节课中,我们已经给出了详细的需求描述,为了方便你查看,我把它重新贴在了下面。
调用方进行接口请求的时候,将 URL、AppID、密码、时间戳拼接在一起,通过加密算法生成 token,并且将 token、AppID、时间戳拼接在 URL 中,一并发送到微服务端。
微服务端在接收到调用方的接口请求之后,从请求中拆解出 token、AppID、时间戳。
微服务端首先检查传递过来的时间戳跟当前时间,是否在 token 失效时间窗口内。如果已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求。
如果 token 验证没有过期失效,微服务端再从自己的存储中,取出 AppID 对应的密码,通过同样的 token 生成算法,生成另外一个 token,与调用方传递过来的 token 进行匹配。如果一致,则鉴权成功,允许接口调用;否则就拒绝接口调用。
首先,我们要做的是逐句阅读上面的需求描述,拆解成小的功能点,一条一条罗列下来。注意,拆解出来的每个功能点要尽可能的小。每个功能点只负责做一件很小的事情(专业叫法是“单一职责”,后面章节中我们会讲到)。下面是我逐句拆解上述需求描述之后,得到的功能点列表:
把 URL、AppID、密码、时间戳拼接为一个字符串;
对字符串通过加密算法加密生成 token;
将 token、AppID、时间戳拼接到 URL 中,形成新的 URL;
解析 URL,得到 token、AppID、时间戳等信息;
从存储中取出 AppID 和对应的密码;
根据时间戳判断 token 是否过期失效;
验证两个 token 是否匹配;
从上面的功能列表中,我们发现,1、2、6、7 都是跟 token 有关,负责 token 的生成、验证;3、4 都是在处理 URL,负责 URL 的拼接、解析;5 是操作 AppID 和密码,负责从存储中读取 AppID 和密码。所以,我们可以粗略地得到三个核心的类:AuthToken、Url、CredentialStorage。AuthToken 负责实现 1、2、6、7 这四个操作;Url 负责 3、4 两个操作;CredentialStorage 负责 5 这个操作。
当然,这是一个初步的类的划分,其他一些不重要的、边边角角的类,我们可能暂时没法一下子想全,但这也没关系,面向对象分析、设计、编程本来就是一个循环迭代、不断优化的过程。根据需求,我们先给出一个粗糙版本的设计方案,然后基于这样一个基础,再去迭代优化,会更加容易一些,思路也会更加清晰一些。
不过,我还要再强调一点,接口调用鉴权这个开发需求比较简单,所以,需求对应的面向对象设计并不复杂,识别出来的类也并不多。但如果我们面对的是更加大型的软件开发、更加复杂的需求开发,涉及的功能点可能会很多,对应的类也会比较多,像刚刚那样根据需求逐句罗列功能点的方法,最后会得到一个长长的列表,就会有点凌乱、没有规律。针对这种复杂的需求开发,我们首先要做的是进行模块划分,将需求先简单划分成几个小的、独立的功能模块,然后再在模块内部,应用我们刚刚讲的方法,进行面向对象设计。而模块的划分和识别,跟类的划分和识别,是类似的套路。
2. 定义类及其属性和方法
刚刚我们通过分析需求描述,识别出了三个核心的类,它们分别是 AuthToken、Url 和 CredentialStorage。现在我们来看下,每个类都有哪些属性和方法。我们还是从功能点列表中挖掘。
AuthToken 类相关的功能点有四个:
把 URL、AppID、密码、时间戳拼接为一个字符串;
对字符串通过加密算法加密生成 token;
根据时间戳判断 token 是否过期失效;
验证两个 token 是否匹配。
对于方法的识别,很多面向对象相关的书籍,一般都是这么讲的,识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选。类比一下方法的识别,我们可以把功能点中涉及的名词,作为候选属性,然后同样进行过滤筛选。
我们可以借用这个思路,根据功能点描述,识别出来 AuthToken 类的属性和方法,如下所示:
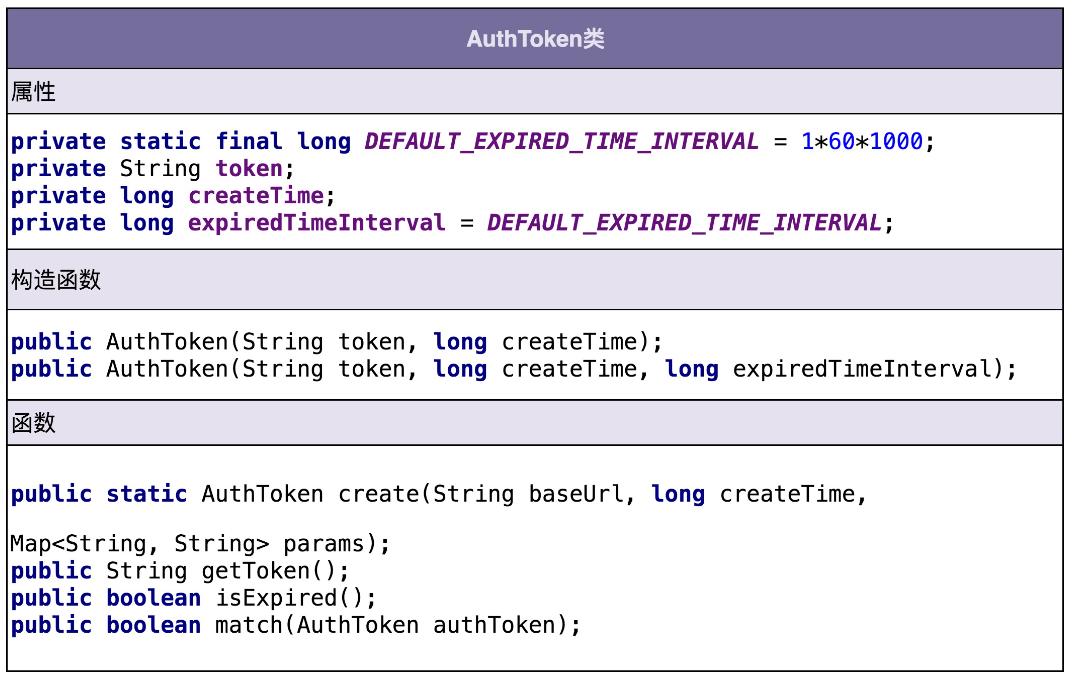
从上面的类图中,我们可以发现这样三个小细节。
第一个细节:并不是所有出现的名词都被定义为类的属性,比如 URL、AppID、密码、时间戳这几个名词,我们把它作为了方法的参数。
第二个细节:我们还需要挖掘一些没有出现在功能点描述中属性,比如 createTime,expireTimeInterval,它们用在 isExpired() 函数中,用来判定 token 是否过期。
第三个细节:我们还给 AuthToken 类添加了一个功能点描述中没有提到的方法 getToken()。
第一个细节告诉我们,从业务模型上来说,不应该属于这个类的属性和方法,不应该被放到这个类里。比如 URL、AppID 这些信息,从业务模型上来说,不应该属于 AuthToken,所以我们不应该放到这个类中。
第二、第三个细节告诉我们,在设计类具有哪些属性和方法的时候,不能单纯地依赖当下的需求,还要分析这个类从业务模型上来讲,理应具有哪些属性和方法。这样可以一方面保证类定义的完整性,另一方面不仅为当下的需求还为未来的需求做些准备。
Url 类相关的功能点有两个:
将 token、AppID、时间戳拼接到 URL 中,形成新的 URL;
解析 URL,得到 token、AppID、时间戳等信息。
虽然需求描述中,我们都是以 URL 来代指接口请求,但是,接口请求并不一定是以 URL 的形式来表达,还有可能是 dubbo RPC 等其他形式。为了让这个类更加通用,命名更加贴切,我们接下来把它命名为 ApiRequest。下面是我根据功能点描述设计的 ApiRequest 类。
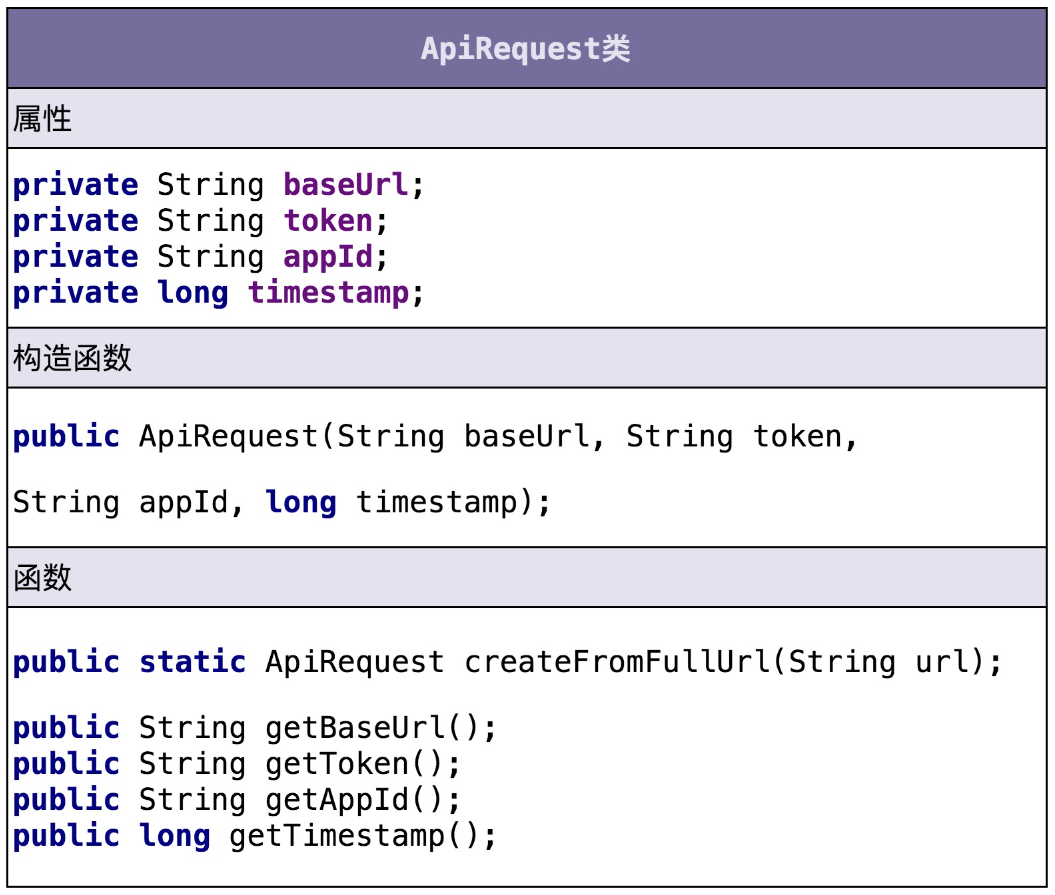
CredentialStorage 类相关的功能点有一个:
从存储中取出 AppID 和对应的密码。
CredentialStorage 类非常简单,类图如下所示。为了做到抽象封装具体的存储方式,我们将 CredentialStorage 设计成了接口,基于接口而非具体的实现编程。

3. 定义类与类之间的交互关系
类与类之间都哪些交互关系呢?UML 统一建模语言中定义了六种类之间的关系。它们分别是:泛化、实现、关联、聚合、组合、依赖。关系比较多,而且有些还比较相近,比如聚合和组合,接下来我就逐一讲解一下。
泛化(Generalization)可以简单理解为继承关系。具体到 Java 代码就是下面这样:
public class A { ... }
public class B extends A { ... }实现(Realization)一般是指接口和实现类之间的关系。具体到 Java 代码就是下面这样:
public interface A {...}
public class B implements A { ... }聚合(Aggregation)是一种包含关系,A 类对象包含 B 类对象,B 类对象的生命周期可以不依赖 A 类对象的生命周期,也就是说可以单独销毁 A 类对象而不影响 B 对象,比如课程与学生之间的关系。具体到 Java 代码就是下面这样:
public class A {
private B b;
public A(B b) {
this.b = b;
}
}组合(Composition)也是一种包含关系。A 类对象包含 B 类对象,B 类对象的生命周期跟依赖 A 类对象的生命周期,B 类对象不可单独存在,比如鸟与翅膀之间的关系。具体到 Java 代码就是下面这样:
public class A {
private B b;
public A() {
this.b = new B();
}
}关联(Association)是一种非常弱的关系,包含聚合、组合两种关系。具体到代码层面,如果 B 类对象是 A 类的成员变量,那 B 类和 A 类就是关联关系。具体到 Java 代码就是下面这样:
public class A {
private B b;
public A(B b) {
this.b = b;
}
}
或者
public class A {
private B b;
public A() {
this.b = new B();
}
}依赖(Dependency)是一种比关联关系更加弱的关系,包含关联关系。不管是 B 类对象是 A 类对象的成员变量,还是 A 类的方法使用 B 类对象作为参数或者返回值、局部变量,只要 B 类对象和 A 类对象有任何使用关系,我们都称它们有依赖关系。具体到 Java 代码就是下面这样:
public class A {
private B b;
public A(B b) {
this.b = b;
}
}
或者
public class A {
private B b;
public A() {
this.b = new B();
}
}
或者
public class A {
public void func(B b) { ... }
}看完了 UML 六种类关系的详细介绍,不知道你有何感受?我个人觉得这样拆分有点太细,增加了学习成本,对于指导编程开发没有太大意义。所以,我从更加贴近编程的角度,对类与类之间的关系做了调整,只保留了四个关系:泛化、实现、组合、依赖,这样你掌握起来会更加容易。
其中,泛化、实现、依赖的定义不变,组合关系替代 UML 中组合、聚合、关联三个概念,也就相当于重新命名关联关系为组合关系,并且不再区分 UML 中的组合和聚合两个概念。之所以这样重新命名,是为了跟我们前面讲的“多用组合少用继承”设计原则中的“组合”统一含义。只要 B 类对象是 A 类对象的成员变量,那我们就称,A 类跟 B 类是组合关系。
理论的东西讲完了,让我们来看一下,刚刚我们定义的类之间都有哪些关系呢?因为目前只有三个核心的类,所以只用到了实现关系,也即 CredentialStorage 和 MysqlCredentialStorage 之间的关系。接下来讲到组装类的时候,我们还会用到依赖关系、组合关系,但是泛化关系暂时没有用到。
4. 将类组装起来并提供执行入口
类定义好了,类之间必要的交互关系也设计好了,接下来我们要将所有的类组装在一起,提供一个执行入口。这个入口可能是一个 main() 函数,也可能是一组给外部用的 API 接口。通过这个入口,我们能触发整个代码跑起来。
接口鉴权并不是一个独立运行的系统,而是一个集成在系统上运行的组件,所以,我们封装所有的实现细节,设计了一个最顶层的 ApiAuthencator 接口类,暴露一组给外部调用者使用的 API 接口,作为触发执行鉴权逻辑的入口。具体的类的设计如下所示:

如何进行面向对象编程?
面向对象设计完成之后,我们已经定义清晰了类、属性、方法、类之间的交互,并且将所有的类组装起来,提供了统一的执行入口。接下来,面向对象编程的工作,就是将这些设计思路翻译成代码实现。有了前面的类图,这部分工作相对来说就比较简单了。所以,这里我只给出比较复杂的 ApiAuthencator 的实现。
对于 AuthToken、ApiRequest、CredentialStorage 这三个类,在这里我就不给出具体的代码实现了。给你留一个课后作业,你可以试着把整个鉴权框架自己去实现一遍。
public interface ApiAuthencator {
void auth(String url);
void auth(ApiRequest apiRequest);
}
public class DefaultApiAuthencatorImpl implements ApiAuthencator {
private CredentialStorage credentialStorage;
public ApiAuthencator() {
this.credentialStorage = new MysqlCredentialStorage();
}
public ApiAuthencator(CredentialStorage credentialStorage) {
this.credentialStorage = credentialStorage;
}
@Override
public void auth(String url) {
ApiRequest apiRequest = ApiRequest.buildFromUrl(url);
auth(apiRequest);
}
@Override
public void auth(ApiRequest apiRequest) {
String appId = apiRequest.getAppId();
String token = apiRequest.getToken();
long timestamp = apiRequest.getTimestamp();
String originalUrl = apiRequest.getOriginalUrl();
AuthToken clientAuthToken = new AuthToken(token, timestamp);
if (clientAuthToken.isExpired()) {
throw new RuntimeException("Token is expired.");
}
String password = credentialStorage.getPasswordByAppId(appId);
AuthToken serverAuthToken = AuthToken.generate(originalUrl, appId, password, timestamp);
if (!serverAuthToken.match(clientAuthToken)) {
throw new RuntimeException("Token verfication failed.");
}
}
}辩证思考与灵活应用
在之前的讲解中,面向对象分析、设计、实现,每个环节的界限划分都比较清楚。而且,设计和实现基本上是按照功能点的描述,逐句照着翻译过来的。这样做的好处是先做什么、后做什么,非常清晰、明确,有章可循,即便是没有太多设计经验的初级工程师,都可以按部就班地参照着这个流程来做分析、设计和实现。
不过,在平时的工作中,大部分程序员往往都是在脑子里或者草纸上完成面向对象分析和设计,然后就开始写代码了,边写边思考边重构,并不会严格地按照刚刚的流程来执行。而且,说实话,即便我们在写代码之前,花很多时间做分析和设计,绘制出完美的类图、UML 图,也不可能把每个细节、交互都想得很清楚。在落实到代码的时候,我们还是要反复迭代、重构、打破重写。
毕竟,整个软件开发本来就是一个迭代、修修补补、遇到问题解决问题的过程,是一个不断重构的过程。我们没法严格地按照顺序执行各个步骤。这就类似你去学驾照,驾校教的都是比较正规的流程,先做什么,后做什么,你只要照着做就能顺利倒车入库,但实际上,等你开熟练了,倒车入库很多时候靠的都是经验和感觉。
总结
今天的内容到此就讲完了。我们一块来总结回顾一下,你需要掌握的一些重点内容。
针对框架、类库、组件等非业务系统的开发,其中一个比较大的难点就是,需求一般都比较抽象、模糊,需要你自己去挖掘,做合理取舍、权衡、假设,把抽象的问题具象化,最终产生清晰的、可落地的需求定义。需求定义是否清晰、合理,直接影响了后续的设计、编码实现是否顺畅。所以,作为程序员,你一定不要只关心设计与实现,前期的需求分析同等重要。
需求分析的过程实际上是一个不断迭代优化的过程。我们不要试图一下就能给出一个完美的解决方案,而是先给出一个粗糙的、基础的方案,有一个迭代的基础,然后再慢慢优化,这样一个思考过程能让我们摆脱无从下手的窘境。
面向对象分析的产出是详细的需求描述。面向对象设计的产出是类。在面向对象设计这一环节中,我们将需求描述转化为具体的类的设计。这个环节的工作可以拆分为下面四个部分。
1. 划分职责进而识别出有哪些类
根据需求描述,我们把其中涉及的功能点,一个一个罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,可否归为同一个类。
2. 定义类及其属性和方法
我们识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选出真正的方法,把功能点中涉及的名词,作为候选属性,然后同样再进行过滤筛选。
3. 定义类与类之间的交互关系
UML 统一建模语言中定义了六种类之间的关系。它们分别是:泛化、实现、关联、聚合、组合、依赖。我们从更加贴近编程的角度,对类与类之间的关系做了调整,保留四个关系:泛化、实现、组合、依赖。
4. 将类组装起来并提供执行入口
我们要将所有的类组装在一起,提供一个执行入口。这个入口可能是一个 main() 函数,也可能是一组给外部用的 API 接口。通过这个入口,我们能触发整个代码跑起来。