Lottery项目所用到的设计模式
Lottery项目所用到的设计模式
1. 简单工厂
工厂模式主要解决什么问题?
当创建逻辑比较复杂,是一个“大工程”的时候,我们就考虑使用工厂模式,封装对象的创建过程,将对象的创建和使用相分离。何为创建逻辑比较复杂呢?我总结了下面两种情况。
- 第一种情况:类似规则配置解析的例子,代码中存在 if-else 分支判断,动态地根据不同的类型创建不同的对象。针对这种情况,我们就考虑使用工厂模式,将这一大坨 if-else 创建对象的代码抽离出来,放到工厂类中。
- 还有一种情况,尽管我们不需要根据不同的类型创建不同的对象,但是,单个对象本身的创建过程比较复杂,比如前面提到的要组合其他类对象,做各种初始化操作。在这种情况下,我们也可以考虑使用工厂模式,将对象的创建过程封装到工厂类中。
对于第一种情况,当每个对象的创建逻辑都比较简单的时候,我推荐使用简单工厂模式,将多个对象的创建逻辑放到一个工厂类中。当每个对象的创建逻辑都比较复杂的时候,为了避免设计一个过于庞大的简单工厂类,我推荐使用工厂方法模式,将创建逻辑拆分得更细,每个对象的创建逻辑独立到各自的工厂类中。
对于第二种情况,因为单个对象本身的创建逻辑就比较复杂,所以,建议使用工厂方法模式。
除了刚刚提到的这几种情况之外,如果创建对象的逻辑并不复杂,那我们就直接通过 new 来创建对象就可以了,不需要使用工厂模式。
现在,我们上升一个思维层面来看工厂模式,它的作用无外乎下面这四个。这也是判断要不要使用工厂模式的最本质的参考标准。
- 封装变化:创建逻辑有可能变化,封装成工厂类之后,创建逻辑的变更对调用者透明。
- 代码复用:创建代码抽离到独立的工厂类之后可以复用。
- 隔离复杂性:封装复杂的创建逻辑,调用者无需了解如何创建对象。
- 控制复杂度:将创建代码抽离出来,让原本的函数或类职责更单一,代码更简洁.
该项目使用了简单工厂,那么简单工厂和工厂方法模式有什么区别呢?其实上面已经说过了,再总结一下。
之所以将某个代码块剥离出来,独立为函数或者类,原因是这个代码块的逻辑过于复杂,剥离之后能让代码更加清晰,更加可读、可维护。但是,如果代码块本身并不复杂,就几行代码而已,我们完全没必要将它拆分成单独的函数或者类。
有两种情况使用工厂方法模式更好:
基于这个设计思想,当对象的创建逻辑比较复杂,不只是简单的 new 一下就可以,而是要组合其他类对象,做各种初始化操作的时候,我们推荐使用工厂方法模式,将复杂的创建逻辑拆分到多个工厂类中,让每个工厂类都不至于过于复杂。而使用简单工厂模式,将所有的创建逻辑都放到一个工厂类中,会导致这个工厂类变得很复杂。
除此之外,在某些场景下,如果对象不可复用,那工厂类每次都要返回不同的对象。如果我们使用简单工厂模式来实现,就只能选择第一种包含 if 分支逻辑的实现方式。如果我们还想避免烦人的 if-else 分支逻辑,这个时候,我们就推荐使用工厂方法模式。
工厂模式和策略模式的区别是什么?
以下,我的理解(不一定对哈):
- 创建模式,工厂模式;
- 行为模式,策略模式;
两个出发点都不太一样;
- 创建模式,关注点在如何创建;
- 行为模式,关注点在行为本身;例如,某个活动,有很多中优惠的策略算法,关注点一般在策略算法本身的,而不是如何创建出来策略算法;
他们经常会一起使用,工厂创建出来策略算法,根据规则选择不同的策略的算法;
该项目的简单工厂在award领域有用到,在策略模式也有用到,这里都讲一下。
1.1 在发奖领域的运用
1.1 代码结构
lottery-domain
└── src
└── main
└── java
└── cn.itedus.lottery.domain.award
├── model
├── repository
│ ├── impl
│ │ └── AwardRepository
│ └── IAwardRepository
└── service
├── factory
│ ├── DistributionGoodsFactory.java
│ └── GoodsConfig.java
└── goods
├── impl
│ ├── CouponGoods.java
│ ├── DescGoods.java
│ ├── PhysicalGoods.java
│ └── RedeemCodeGoods.java
├── DistributionBase.java
└── IDistributionGoodsc.java1.2 发奖适配策略
public interface IDistributionGoods {
DistributionRes doDistribution(GoodsReq req);
}IDistributionGoods的实现略。
1.3 定义简单工厂
如下所示,把四种奖品放到一个统一的配置文件类 Map 中,便于通过 AwardType 获取相应的对象,减少 if...else 的使用。
public class GoodsConfig {
/** 奖品发放策略组 */
protected static Map<Integer, IDistributionGoods> goodsMap = new ConcurrentHashMap<>();
@Resource
private DescGoods descGoods;
@Resource
private RedeemCodeGoods redeemCodeGoods;
@Resource
private CouponGoods couponGoods;
@Resource
private PhysicalGoods physicalGoods;
@PostConstruct
public void init() {
goodsMap.put(Constants.AwardType.DESC.getCode(), descGoods);
goodsMap.put(Constants.AwardType.RedeemCodeGoods.getCode(), redeemCodeGoods);
goodsMap.put(Constants.AwardType.CouponGoods.getCode(), couponGoods);
goodsMap.put(Constants.AwardType.PhysicalGoods.getCode(), physicalGoods);
}
}如下所示,定义好简单工厂以后,DistributionGoodsFactory.java 继承 GoodsConfig.class 来使用工厂中的奖品来发奖,调用1.2 发奖适配策略中的接口。
@Service
public class DistributionGoodsFactory extends GoodsConfig {
public IDistributionGoods getDistributionGoodsService(Integer awardType){
return goodsMap.get(awardType);
}
}1.2 配合策略模式使用
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,我们需要对客户端代码屏蔽创建细节。我们可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。
public class DrawConfig {
@Resource
private IDrawAlgorithm entiretyRateRandomDrawAlgorithm;
@Resource
private IDrawAlgorithm singleRateRandomDrawAlgorithm;
/** 抽奖策略组 */
protected static Map<Integer, IDrawAlgorithm> drawAlgorithmGroup = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
drawAlgorithmGroup.put(Constants.StrategyMode.ENTIRETY.getCode(), entiretyRateRandomDrawAlgorithm);
drawAlgorithmGroup.put(Constants.StrategyMode.SINGLE.getCode(), singleRateRandomDrawAlgorithm);
}
}2. 策略模式
策略模式,英文全称是 Strategy Design Pattern。在 GoF 的《设计模式》一书中,它是这样定义的:
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
翻译成中文就是:定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)。我们知道,工厂模式是解耦对象的创建和使用,策略模式也能起到解耦的作用,不过,它解耦的是策略的定义、创建、使用这三部分。接下来,我就详细讲讲一个完整的策略模式应该包含的这三个部分。
2.1 抽奖策略
2.1.1 策略的定义
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以,客户端代码基于接口而非实现编程,可以灵活地替换不同的策略。示例代码如下所示:
public interface IDrawAlgorithm {
void initRateTuple(Long strategyId,Integer strategyMode, List<AwardRateInfo> awardRateInfoList);
boolean isExist(Long strategyId);
String randomDraw(Long strategyId, List<String> excludeAwardIds);
}
public abstract class BaseAlgorithm implements IDrawAlgorithm {
//略
}
@Component("singleRateRandomDrawAlgorithm")
public class SingleRateRandomDrawAlgorithm extends BaseAlgorithm {
@Override
public String randomDraw(Long strategyId, List<String> excludeAwardIds) {
//略
}
}
@Component("entiretyRateRandomDrawAlgorithm")
public class EntiretyRateRandomDrawAlgorithm extends BaseAlgorithm {
@Override
public String randomDraw(Long strategyId, List<String> excludeAwardIds) {
//略
}
}2.1.2 策略的创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,我们需要对客户端代码屏蔽创建细节。我们可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。示例代码如下所示:
public class DrawConfig {
@Resource
private IDrawAlgorithm entiretyRateRandomDrawAlgorithm;
@Resource
private IDrawAlgorithm singleRateRandomDrawAlgorithm;
/** 抽奖策略组 */
protected static Map<Integer, IDrawAlgorithm> drawAlgorithmGroup = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
drawAlgorithmGroup.put(Constants.StrategyMode.ENTIRETY.getCode(), entiretyRateRandomDrawAlgorithm);
drawAlgorithmGroup.put(Constants.StrategyMode.SINGLE.getCode(), singleRateRandomDrawAlgorithm);
}
}可以讲一下有状态的创建。
2.1.3 策略的使用
我们知道,策略模式包含一组可选策略,客户端代码一般如何确定使用哪个策略呢?最常见的是运行时动态确定使用哪种策略,这也是策略模式最典型的应用场景。
这里的“运行时动态”指的是,我们事先并不知道会使用哪个策略,而是在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。接下来,我们通过一个例子来解释一下。
如之下的代码,test_iDrawExec这个函数将DrawReq传给了doDrawExec方法,而在这个方法中,通过drawAlgorithmGroup.get(strategy.getStrategyMode())判断具体使用了哪个策略。所以这个是在程序的执行过程中,通过用户的输入来确定具体用哪个抽奖策略。
而test_randomDrawAlgorithm直接使用了randomDrawAlgorithm属性,该属性已经被注解 @Resource(name = "entiretyRateRandomDrawAlgorithm")指定了具体的策略,是“非运行时动态确定的”,并不能发挥策略模式的优势。在这种应用场景下,策略模式实际上退化成了“面向对象的多态特性”或“基于接口而非实现编程原则”。这种方法也等同于从Map中直接取一个策略。
public class DrawAlgorithmTest {
private Logger logger = LoggerFactory.getLogger(SpringRunnerTest.class);
@Resource(name = "entiretyRateRandomDrawAlgorithm")
private IDrawAlgorithm randomDrawAlgorithm;
@Resource(name = "drawExec")
private IDrawExec iDrawExec;
@Before
public void init() {
// 奖品信息
List<AwardRateInfo> strategyList = new ArrayList<>();
strategyList.add(new AwardRateInfo("一等奖:IMac", new BigDecimal("0.05")));
strategyList.add(new AwardRateInfo("二等奖:iphone", new BigDecimal("0.15")));
strategyList.add(new AwardRateInfo("三等奖:ipad", new BigDecimal("0.20")));
strategyList.add(new AwardRateInfo("四等奖:AirPods", new BigDecimal("0.25")));
strategyList.add(new AwardRateInfo("五等奖:充电宝", new BigDecimal("0.35")));
// 初始数据
randomDrawAlgorithm.initRateTuple(100001L, Constants.StrategyMode.SINGLE.getCode(), strategyList);
}
@Test
public void test_randomDrawAlgorithm() {
List<String> excludeAwardIds = new ArrayList<>();
excludeAwardIds.add("二等奖:iphone");
excludeAwardIds.add("四等奖:AirPods");
for (int i = 0; i < 20; i++) {
System.out.println("中奖结果:" + randomDrawAlgorithm.randomDraw(100001L, excludeAwardIds));
}
}
@Test
public void test_iDrawExec() {
DrawResult drawResult = iDrawExec.doDrawExec(new DrawReq("小傅哥", 10001L));
logger.info("测试结果:{}", JSON.toJSONString(drawResult));
}
}2.2 ID生成策略
2.2.1 策略的定义
public interface IIdGenerator {
/**
* 获取ID,目前有两种实现方式
* 1. 雪花算法,用于生成单号
* 2. 日期算法,用于生成活动编号类,特性是生成数字串较短,但指定时间内不能生成太多
* 3. 随机算法,用于生成策略ID
*
* @return ID
*/
long nextId();
}
@Component
public class SnowFlake implements IIdGenerator {
//略
}
@Component
public class ShortCode implements IIdGenerator {
//略
}
@Component
public class RandomNumeric implements IIdGenerator {
//略
}2.2.2 策略的创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,我们需要对客户端代码屏蔽创建细节。我们可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。示例代码如下所示:
@Configuration
public class IdContext {
/**
* 创建 ID 生成策略对象,属于策略设计模式的使用方式
*
* @param snowFlake 雪花算法,长码,大量
* @param shortCode 日期算法,短码,少量,全局唯一需要自己保证
* @param randomNumeric 随机算法,短码,大量,全局唯一需要自己保证
* @return IIdGenerator 实现类
*/
@Bean
public Map<Constants.Ids, IIdGenerator> idGenerator(SnowFlake snowFlake, ShortCode shortCode, RandomNumeric randomNumeric) {
Map<Constants.Ids, IIdGenerator> idGeneratorMap = new HashMap<>(8);
idGeneratorMap.put(Constants.Ids.SnowFlake, snowFlake);
idGeneratorMap.put(Constants.Ids.ShortCode, shortCode);
idGeneratorMap.put(Constants.Ids.RandomNumeric, randomNumeric);
return idGeneratorMap;
}
}2.2.3 策略的使用
@RunWith(SpringRunner.class)
@SpringBootTest
public class SupportTest {
private Logger logger = LoggerFactory.getLogger(SupportTest.class);
@Resource
private Map<Constants.Ids, IIdGenerator> idGeneratorMap;
@Test
public void test_ids() {
logger.info("雪花算法策略,生成ID:{}", idGeneratorMap.get(Constants.Ids.SnowFlake).nextId());
logger.info("日期算法策略,生成ID:{}", idGeneratorMap.get(Constants.Ids.ShortCode).nextId());
logger.info("随机算法策略,生成ID:{}", idGeneratorMap.get(Constants.Ids.RandomNumeric).nextId());
}
}上面是静态获取的方法(非语法上的静态,是逻辑上的静态),之后的分支应该会有动态,此处待补充。
3. 模板模式
模板模式,全称是模板方法设计模式,英文是 Template Method Design Pattern。在 GoF 的《设计模式》一书中,它是这么定义的:
Define the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.
翻译成中文就是:模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。这里的“算法”,我们可以理解为广义上的“业务逻辑”,并不特指数据结构和算法中的“算法”。这里的算法骨架就是“模板”,包含算法骨架的方法就是“模板方法”,这也是模板方法模式名字的由来。
模板模式有两大作用:复用和扩展。其中,复用指的是,所有的子类可以复用父类中提供的模板方法的代码。扩展指的是,框架通过模板模式提供功能扩展点,让框架用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能。
在Lottery项目中,只用到了其中的复用功能。
模板模式把一个算法中不变的流程抽象到父类的模板方法 templateMethod() 中,将可变的部分 method1()、method2() 留给子类 ContreteClass1 和 ContreteClass2 来实现。所有的子类都可以复用父类中模板方法定义的流程代码。
public abstract class AbstractClass {
public final void templateMethod() {
//...
method1();
//...
method2();
//...
}
protected abstract void method1();
protected abstract void method2();
}
public class ConcreteClass1 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
public class ConcreteClass2 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
AbstractClass demo = ConcreteClass1();
demo.templateMethod();3.1 模板模式在Lottery的应用概述
本章节最大的目标在于把抽奖流程标准化,需要考虑的一条思路线包括:
- 根据入参策略ID获取抽奖策略配置
- 校验和处理抽奖策略的数据初始化到内存
- 获取那些被排除掉的抽奖列表,这些奖品可能是已经奖品库存为空,或者因为风控策略不能给这个用户薅羊毛的奖品
- 执行抽奖算法
- 包装中奖结果
以上这些步骤就是需要在抽奖执行类的方法中需要处理的内容,如果是在一个类的一个方法中,顺序开发这些内容也是可以实现的。但这样的代码实现过程是不易于维护的,也不太方便在各个流程节点扩展其他功能,也会使一个类的代码越来越庞大,因此对于这种可以制定标准流程的功能逻辑,通常使用模板方法模式是非常合适的。接下来我们就来通过这样的设计模式来开发实现下代码逻辑。
代码结构如下:
lottery-domain
└── src
└── main
└── java
└── cn.itedus.lottery.domain.strategy
├── model
├── repository
│ ├── impl
│ │ └── StrategyRepository
│ └── IStrategyRepository
└── service
├── algorithm
│ ├── impl
│ │ ├── EntiretyRateRandomDrawAlgorithm.java
│ │ └── SingleRateRandomDrawAlgorithm.java
│ ├── BaseAlgorithm.java
│ └── IDrawAlgorithm.java
└── draw
├── impl
│ └── DrawExecImpl.java
├── AbstractDrawBase.java
├── DrawConfig.java
├── DrawStrategySupport.java
└── IDrawExec.java本节的模板模式的使用主要在于对领域模块 lottery-domain.strategy 中 draw 抽奖包下的类处理。
DrawConfig:配置抽奖策略,SingleRateRandomDrawAlgorithm、EntiretyRateRandomDrawAlgorithm
DrawStrategySupport:提供抽奖策略数据支持,便于查询策略配置、奖品信息。通过这样的方式隔离职责。
AbstractDrawBase:抽象类定义模板方法流程,在抽象类的 doDrawExec 方法中,处理整个抽奖流程,并提供在流程中需要使用到的抽象方法,由 DrawExecImpl 服务逻辑中做具体实现。
3.2 定义抽象的抽奖过程
public abstract class AbstractDrawBase extends DrawStrategySupport implements IDrawExec {
private Logger logger = LoggerFactory.getLogger(AbstractDrawBase.class);
@Override
public DrawResult doDrawExec(DrawReq req) {
// 1. 获取抽奖策略
StrategyRich strategyRich = super.queryStrategyRich(req.getStrategyId());
Strategy strategy = strategyRich.getStrategy();
// 2. 校验抽奖策略是否已经初始化到内存
this.checkAndInitRateData(req.getStrategyId(), strategy.getStrategyMode(), strategyRich.getStrategyDetailList());
// 3. 获取不在抽奖范围内的列表,包括:奖品库存为空、风控策略、临时调整等
List<String> excludeAwardIds = this.queryExcludeAwardIds(req.getStrategyId());
// 4. 执行抽奖算法
String awardId = this.drawAlgorithm(req.getStrategyId(), drawAlgorithmGroup.get(strategy.getStrategyMode()), excludeAwardIds);
// 5. 包装中奖结果
return buildDrawResult(req.getuId(), req.getStrategyId(), awardId);
}
/**
* 获取不在抽奖范围内的列表,包括:奖品库存为空、风控策略、临时调整等,这类数据是含有业务逻辑的,所以需要由具体的实现方决定
*
* @param strategyId 策略ID
* @return 排除的奖品ID集合
*/
protected abstract List<String> queryExcludeAwardIds(Long strategyId);
/**
* 执行抽奖算法
*
* @param strategyId 策略ID
* @param drawAlgorithm 抽奖算法模型
* @param excludeAwardIds 排除的抽奖ID集合
* @return 中奖奖品ID
*/
protected abstract String drawAlgorithm(Long strategyId, IDrawAlgorithm drawAlgorithm, List<String> excludeAwardIds);
}抽象类 AbstractDrawBase 继承了 DrawStrategySupport 类包装的配置和数据查询功能,并实现接口 IDrawExec#doDrawExec 方法,对抽奖进行编排操作。
在 doDrawExec 方法中,主要定义了5个步骤:获取抽奖策略、校验抽奖策略是否已经初始化到内存、获取不在抽奖范围内的列表,包括:奖品库存为空、风控策略、临时调整等、执行抽奖算法、包装中奖结果,和2个抽象方法 queryExcludeAwardIds、drawAlgorithm,具体实现内容可以在代码中查看调试。
3.2 定义抽象的抽奖过程的子类
@Service("drawExec")
public class DrawExecImpl extends AbstractDrawBase {
private Logger logger = LoggerFactory.getLogger(DrawExecImpl.class);
@Override
protected List<String> queryExcludeAwardIds(Long strategyId) {
List<String> awardList = strategyRepository.queryNoStockStrategyAwardList(strategyId);
logger.info("执行抽奖策略 strategyId:{},无库存排除奖品列表ID集合 awardList:{}", strategyId, JSON.toJSONString(awardList));
return awardList;
}
@Override
protected String drawAlgorithm(Long strategyId, IDrawAlgorithm drawAlgorithm, List<String> excludeAwardIds) {
// 执行抽奖
String awardId = drawAlgorithm.randomDraw(strategyId, excludeAwardIds);
// 判断抽奖结果
if (null == awardId) {
return null;
}
/*
* 扣减库存,暂时采用数据库行级锁的方式进行扣减库存,后续优化为 Redis 分布式锁扣减 decr/incr
* 注意:通常数据库直接锁行记录的方式并不能支撑较大体量的并发,但此种方式需要了解,因为在分库分表下的正常数据流量下的个人数据记录中,是可以使用行级锁的,因为他只影响到自己的记录,不会影响到其他人
*/
boolean isSuccess = strategyRepository.deductStock(strategyId, awardId);
// 返回结果,库存扣减成功返回奖品ID,否则返回NULL 「在实际的业务场景中,如果中奖奖品库存为空,则会发送兜底奖品,比如各类券」
return isSuccess ? awardId : null;
}
}抽象方法的具体实现类 DrawExecImpl,分别实现了 queryExcludeAwardIds、drawAlgorithm 两个方法,之所以定义这2个抽象方法,是因为这2个方法可能随着实现方有不同的方式变化,不适合定义成通用的方法。
queryExcludeAwardIds:排除奖品ID,可以包含无库存奖品,也可能是业务逻辑限定的风控策略排除奖品等,所以交给业务实现类做具体处理。
drawAlgorithm:是算法抽奖的具体调用处理,因为这里还需要对策略库存进行处理,所以需要单独包装。注意代码注释,扣减库存
4. 状态模式
虽然网上有各种状态模式的定义,但是只要记住状态模式是状态机的一种实现方式即可。状态机又叫有限状态机,它有 3 个部分组成:状态、事件、动作。其中,事件也称为转移条件。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
针对状态机,今天我们总结了三种实现方式。
第一种实现方式叫分支逻辑法。利用 if-else 或者 switch-case 分支逻辑,参照状态转移图,将每一个状态转移原模原样地直译成代码。对于简单的状态机来说,这种实现方式最简单、最直接,是首选。
第二种实现方式叫查表法。对于状态很多、状态转移比较复杂的状态机来说,查表法比较合适。通过二维数组来表示状态转移图,能极大地提高代码的可读性和可维护性。
第三种实现方式叫状态模式。对于状态并不多、状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能比较复杂的状态机来说,我们首选这种实现方式。
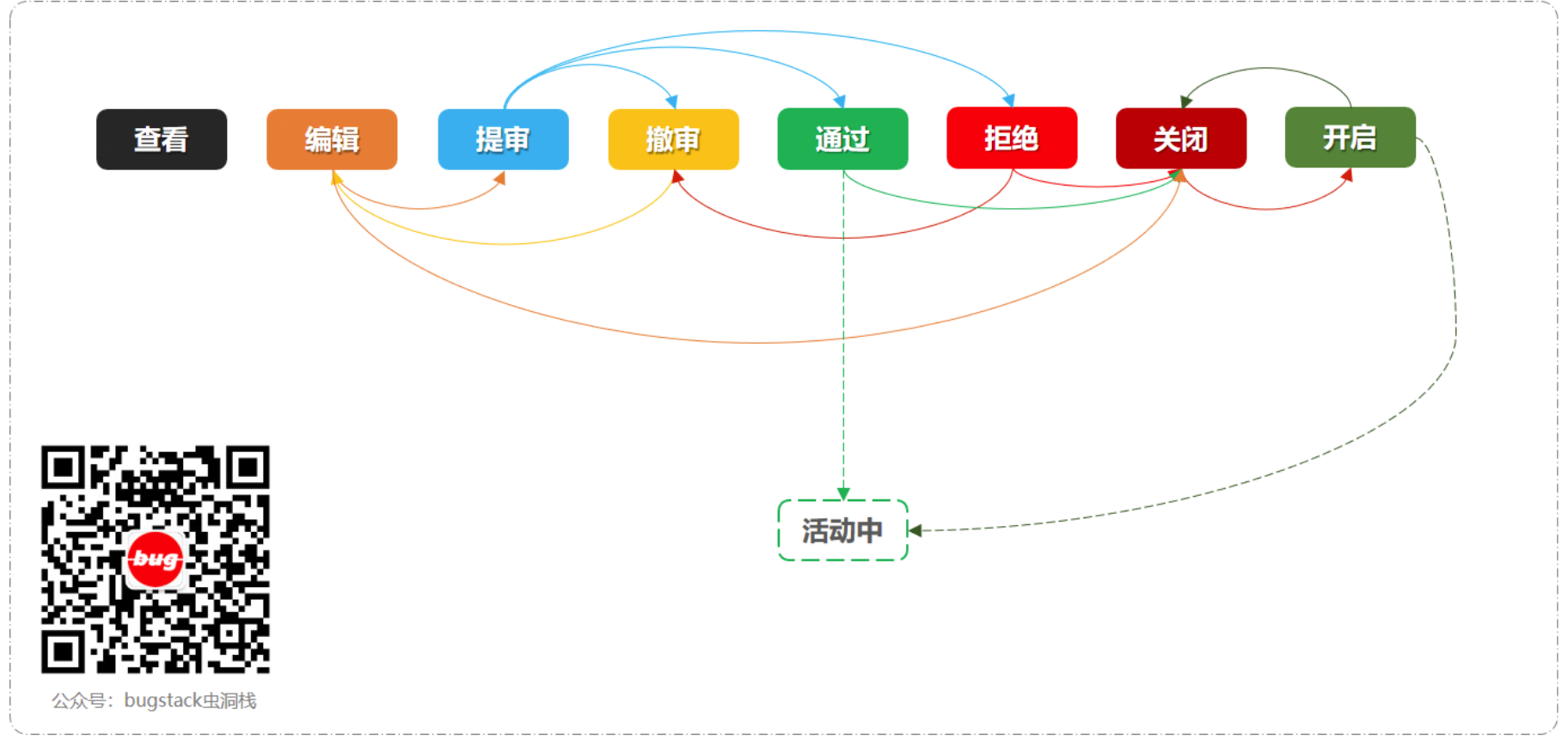
在Lottery项目中,就用的是第三种实现方法,即状态模式。项目的活动状态流转如下图所示:
4.1 代码结构
lottery-domain
└── src
└── main
└── java
└── cn.itedus.lottery.domain.activity
├── model
├── repository
│ └── IActivityRepository
└── service
├── deploy
├── partake [待开发]
└── stateflow
├── event
│ ├── ArraignmentState.java
│ ├── CloseState.java
│ ├── DoingState.java
│ ├── EditingState.java
│ ├── OpenState.java
│ ├── PassState.java
│ └── RefuseState.java
├── impl
│ └── StateHandlerImpl.java
├── AbstractState.java
├── IStateHandler.java
└── StateConfig.javaactivity 活动领域层包括:deploy、partake、stateflow
stateflow 状态流转运用的状态模式,主要包括抽象出状态抽象类AbstractState 和对应的 event 包下的状态处理,最终使用 StateHandlerImpl 来提供对外的接口服务。
4.2 状态类
public abstract class AbstractState {
@Resource
protected IActivityRepository activityRepository;
/**
* 活动提审
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result arraignment(Long activityId, Enum<Constants.ActivityState> currentState);
/**
* 审核通过
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result checkPass(Long activityId, Enum<Constants.ActivityState> currentState);
/**
* 审核拒绝
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result checkRefuse(Long activityId, Enum<Constants.ActivityState> currentState);
/**
* 撤审撤销
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result checkRevoke(Long activityId, Enum<Constants.ActivityState> currentState);
/**
* 活动关闭
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result close(Long activityId, Enum<Constants.ActivityState> currentState);
/**
* 活动开启
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result open(Long activityId, Enum<Constants.ActivityState> currentState);
/**
* 活动执行
*
* @param activityId 活动ID
* @param currentState 当前状态
* @return 执行结果
*/
public abstract Result doing(Long activityId, Enum<Constants.ActivityState> currentState);
}提供了一个状态类的虚类,也是所有状态的父类。里面包含了许多虚的方法,待子类继承,然后进行具体的实现。包括了:活动提审、审核通过、审核拒绝、撤审撤销等7个方法。在这些方法中所有的入参都是一样的,activityId(活动ID)、currentStatus(当前状态),只有他们的具体实现是不同的。下面看看提审状态,提审状态的的活动只能被撤审、通过和拒绝。
@Component
public class ArraignmentState extends AbstractState {
@Override
public Result arraignment(Long activityId, Enum<Constants.ActivityState> currentState) {
return Result.buildResult(Constants.ResponseCode.UN_ERROR, "待审核状态不可重复提审");
}
@Override
public Result checkPass(Long activityId, Enum<Constants.ActivityState> currentState) {
boolean isSuccess = activityRepository.alterStatus(activityId, currentState, Constants.ActivityState.PASS);
return isSuccess ? Result.buildResult(Constants.ResponseCode.SUCCESS, "活动审核通过完成") : Result.buildErrorResult("活动状态变更失败");
}
@Override
public Result checkRefuse(Long activityId, Enum<Constants.ActivityState> currentState) {
boolean isSuccess = activityRepository.alterStatus(activityId, currentState, Constants.ActivityState.REFUSE);
return isSuccess ? Result.buildResult(Constants.ResponseCode.SUCCESS, "活动审核拒绝完成") : Result.buildErrorResult("活动状态变更失败");
}
@Override
public Result checkRevoke(Long activityId, Enum<Constants.ActivityState> currentState) {
boolean isSuccess = activityRepository.alterStatus(activityId, currentState, Constants.ActivityState.EDIT);
return isSuccess ? Result.buildResult(Constants.ResponseCode.SUCCESS, "活动审核撤销回到编辑中") : Result.buildErrorResult("活动状态变更失败");
}
@Override
public Result close(Long activityId, Enum<Constants.ActivityState> currentState) {
return Result.buildResult(Constants.ResponseCode.UN_ERROR, "非拒绝活动不可关闭");
}
@Override
public Result open(Long activityId, Enum<Constants.ActivityState> currentState) {
return Result.buildResult(Constants.ResponseCode.UN_ERROR, "非关闭活动不可开启");
}
@Override
public Result doing(Long activityId, Enum<Constants.ActivityState> currentState) {
return Result.buildResult(Constants.ResponseCode.UN_ERROR, "待审核活动不可执行活动中变更");
}
}通过这样的设计模式结构,优化掉原本需要在各个流程节点中的转换使用 ifelse 的场景,这样操作以后也可以更加方便你进行扩展。
4.3 配置状态类
将定义好的7个状态类一一加入到StateConfig的Map中,Key是各个状态的枚举类型,Value是具体的状态类。
public class StateConfig {
@Resource
private ArraignmentState arraignmentState;
@Resource
private CloseState closeState;
@Resource
private DoingState doingState;
@Resource
private EditingState editingState;
@Resource
private OpenState openState;
@Resource
private PassState passState;
@Resource
private RefuseState refuseState;
protected Map<Enum<Constants.ActivityState>, AbstractState> stateGroup = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
stateGroup.put(Constants.ActivityState.ARRAIGNMENT, arraignmentState);
stateGroup.put(Constants.ActivityState.CLOSE, closeState);
stateGroup.put(Constants.ActivityState.DOING, doingState);
stateGroup.put(Constants.ActivityState.EDIT, editingState);
stateGroup.put(Constants.ActivityState.OPEN, openState);
stateGroup.put(Constants.ActivityState.PASS, passState);
stateGroup.put(Constants.ActivityState.REFUSE, refuseState);
}
}4.4 状态处理
@Service
public class StateHandlerImpl extends StateConfig implements IStateHandler {
@Override
public Result arraignment(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).arraignment(activityId, currentStatus);
}
@Override
public Result checkPass(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).checkPass(activityId, currentStatus);
}
@Override
public Result checkRefuse(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).checkRefuse(activityId, currentStatus);
}
@Override
public Result checkRevoke(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).checkRevoke(activityId, currentStatus);
}
@Override
public Result close(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).close(activityId, currentStatus);
}
@Override
public Result open(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).open(activityId, currentStatus);
}
@Override
public Result doing(Long activityId, Enum<Constants.ActivityState> currentStatus) {
return stateGroup.get(currentStatus).doing(activityId, currentStatus);
}
}stateGroup.get(currentStatus)是获取具体某个状态类,然后再调用该状态类中的方法,方法中的逻辑会判断该状态能不能执行某个动作跳转到其他逻辑。同时也会统一用Result类来封装结果。
4.5 状态类的使用
@Test
public void test_alterState() {
logger.info("提交审核,测试:{}", JSON.toJSONString(stateHandler.arraignment(100001L, Constants.ActivityState.EDIT)));
logger.info("审核通过,测试:{}", JSON.toJSONString(stateHandler.checkPass(100001L, Constants.ActivityState.ARRAIGNMENT)));
logger.info("运行活动,测试:{}", JSON.toJSONString(stateHandler.doing(100001L, Constants.ActivityState.PASS)));
logger.info("二次提审,测试:{}", JSON.toJSONString(stateHandler.checkPass(100001L, Constants.ActivityState.EDIT)));
}当活动的状态需要变化时,调用stateHandler中的方法,传入活动id和活动的当前状态,判断是否可以跳转。
5. 组合模式
组合模式的设计思路,与其说是一种设计模式,倒不如说是对业务场景的一种数据结构和算法的抽象。 其中,数据可以表示成树这种数据结构,业务需求可以通过在树上的算法来实现,递归或迭代。
组合模式,将一组对象组织成树形结构,将单个对象和组合对象都看做树中的节点,以统一处理逻辑,并且它利用树形结构的特点,递归地处理每个子树,依次简化代码实现。使用组合模式的前提在于,你的业务场景必须能够表示成树形结构。所以,组合模式的应用场景也比较局限,它并不是一种很常用的设计模式。
常见的场景有:单位的组织架构、军队的建制编排、操作系统的文件目录、决策树。
5.1 决策树表结构描述
3张表共同描述了决策树的结构,分别为:
- 表
rule_tree代表了决策树的根节点,也可以唯一地确定一棵树,其中tree_root_node_id字段是规则树根ID,代表了根节点。 - 表
rule_tree_node代表了决策树的所有节点,其中node_type字段用于区分是否为叶子节点,如果是叶子节点,则给出来决策结果;rule_key字段表示规则key,例如可以是性别或年龄等;node_value在当nodeType为叶子节点时,代表了叶子节点的值,即为该用户可以参加的活动号。 - 表
rule_tree_node_line代表了节点和子节点之间的连线。其中node_id_from字段表示父节点,node_id_to表示子节点。rule_limit_type表示从该父节点到子节点需要满足的约束条件,比如相等的关系,rule_limit_value表示限定值,只有满足和限定值的约束条件,才可以从from节点跳到to这个子节点。
5.2 决策树代码逻辑描述

上图左上角的小图表示了一颗决策树,从根节点开始,到叶子节点可以给出一个决策结果。
5.2.1 树结构组织关系
LogicFilter是一个规则过滤器接口类,有两个接口方法:
filter,传入决策值和决策节点,给出下一个节点的ID;
matterValue,传入决策请求,给出决策值。
BaseLogic是一个基础抽象类,实现了LogicFilter接口类,类的方法实现了接口类中的接口方法。另外实现了逻辑对比的方法,决定是否能跳转到下一个节点。
UserAgeFilter和UserGenderFilter是树节点逻辑实现类,继承于BaseLogic。实现了matterValue方法,获取该节点的值。
5.2.2 树结构执行引擎
前面讲了决策树对应的数据库表结构以及决策树对应的内存结构,内存结构还包括了节点包含的key和value,还有边的约束关系。但是还需要用树的遍历算法执行决策树,这就是树结构的执行引擎。
EngineBase是规则引擎基础类,其中最核心的函数是engineDecisionMaker,它的作用是对于某个决策树,从根节点走到到叶节点,最后给出决策结果。
public class EngineBase extends EngineConfig implements EngineFilter {
private Logger logger = LoggerFactory.getLogger(EngineBase.class);
@Override
public EngineResult process(DecisionMatterReq matter) {
throw new RuntimeException("未实现规则引擎服务");
}
protected TreeNodeVO engineDecisionMaker(TreeRuleRich treeRuleRich, DecisionMatterReq matter) {
TreeRootVO treeRoot = treeRuleRich.getTreeRoot();
Map<Long, TreeNodeVO> treeNodeMap = treeRuleRich.getTreeNodeMap();
// 规则树根ID
Long rootNodeId = treeRoot.getTreeRootNodeId();
TreeNodeVO treeNodeInfo = treeNodeMap.get(rootNodeId);
// 节点类型[NodeType];1子叶、2果实
while (Constants.NodeType.STEM.equals(treeNodeInfo.getNodeType())) {
String ruleKey = treeNodeInfo.getRuleKey();
LogicFilter logicFilter = logicFilterMap.get(ruleKey);
String matterValue = logicFilter.matterValue(matter);
Long nextNode = logicFilter.filter(matterValue, treeNodeInfo.getTreeNodeLineInfoList());
treeNodeInfo = treeNodeMap.get(nextNode);
logger.info("决策树引擎=>{} userId:{} treeId:{} treeNode:{} ruleKey:{} matterValue:{}", treeRoot.getTreeName(), matter.getUserId(), matter.getTreeId(), treeNodeInfo.getTreeNodeId(), ruleKey, matterValue);
}
return treeNodeInfo;
}
}RuleEngineHandle是规则引擎处理器,继承了规则引擎处理类,重写了process方法,这是实际给出决策的方法。该方法调用engineDecisionMaker获得决策结果,将决策结果和其他信息进行包装一起返回。